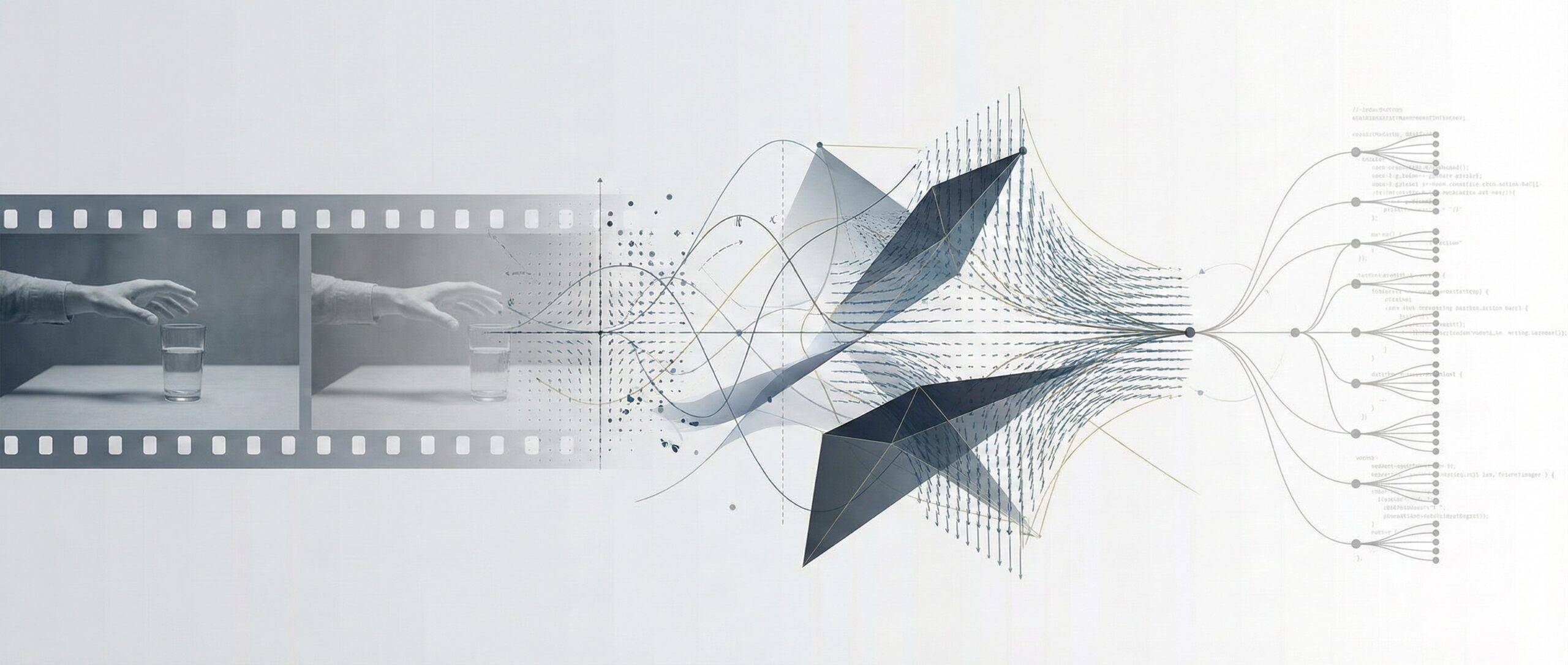
Czy LLM może „zobaczyć” przyszłość?
Eksperyment z modelami świata, reprezentacją latentną i wspólnym językiem wektorów
Nie zacząłem tego projektu po to, żeby udowodnić komuś rację albo ją podważyć.
Zacząłem go z czystej ciekawości.
W sztucznej inteligencji od kilku lat narasta napięcie. Jedni twierdzą, że wystarczy skalować modele językowe — więcej tekstu, więcej parametrów, więcej danych — a inteligencja wyłoni się sama. Inni argumentują, że tekst to tylko opis świata, nie sam świat. Że bez modeli rozumiejących przestrzeń, dynamikę i przyczynowość nigdy nie zbliżymy się do prawdziwej inteligencji.
Zamiast wybierać stronę, postanowiłem sprawdzić coś innego:
Co się stanie, jeśli oba podejścia zaczną mówić tym samym językiem?
I czy tym językiem mogą być nie słowa, ale wektory.
Etap 1: Model, który widzi teraźniejszość zapisaną w liczbach
Mózg: model językowy
Pierwszym krokiem było przygotowanie modelu językowego — Ania 11B** — który miał pełnić rolę warstwy semantycznej systemu. Model został w pełni dostrojony (full fine‑tuning w precyzji bfloat16), aby stabilnie operować w języku polskim i dobrze rozumieć kontekst oraz relacje przyczynowe.
Ale model językowy bez percepcji to tylko generator zdań.
Potrzebne były „oczy”.
Oczy: V‑JEPA 2
Zamiast klasycznego modelu wizyjnego, który generuje opis obrazu, użyłem V‑JEPA 2 (vjepa2-vith-fpc64-256).
To model, który nie produkuje etykiet ani captionów.
On przekształca wideo w reprezentację latentną.
Dla klipu 32 klatek (256×256 pikseli) otrzymujemy tensor:
[2048 tokenów × 1280 wymiarów]To nie są piksele.
To nie są surowe cechy.
To struktura geometryczna sceny w przestrzeni embeddingów.
Każdy klip był zapisywany jako plik .pt (~5 MB).
Nie obraz. Nie tekst. Matematyczna reprezentacja chwili.
Most: Attentive Pooler
Problem był oczywisty: LLM nie rozumie tensorów 2048×1280.
Zbudowałem więc adapter — Attentive Pooler — którego zadaniem było:
- przeskanować 2048 tokenów wizualnych,
- wybrać istotne zależności,
- skompresować je do 512 tokenów,
- przemapować z 1280 → 4096 (przestrzeń embeddingów LLM).
Pipeline wyglądał tak:
Wideo
↓
V-JEPA → [2048, 1280]
↓
Attentive Pooler → [512, 4096]
↓
LLMPo treningu model zaczął opisywać to, co „widział” w reprezentacji:
„Mężczyzna siedzi przy biurku.”
„Sięga po myszkę.”
Nie widział pikseli.
Interpretował geometrię embeddingu.
To był moment, w którym LLM przestał być tylko przetwórcą tekstu.
Stał się interpretatorem reprezentacji.
Ale opisywał wyłącznie teraźniejszość.
Przełom: EB‑JEPA i predykcja reprezentacji
W trakcie dalszych prac pojawiła się architektura EB‑JEPA (Energy‑Based Joint Embedding Predictive Architecture).
Jej fundamentalna idea jest prosta, ale głęboka:
Nie przewiduj pikseli przyszłości.
Przewiduj reprezentację przyszłości.
Zamiast generować kolejną klatkę, model uczy się przewidywać embedding przyszłego stanu świata.
I wtedy pojawiła się myśl:
Skoro LLM już potrafi czytać reprezentację teraźniejszości,
to czy zinterpretuje reprezentację przyszłości?
Czym jest EB‑JEPA w sensie matematycznym?
EB‑JEPA definiuje funkcję energii:
[
E(x, y)
]
gdzie:
- ( x ) — reprezentacja kontekstu (teraźniejszość),
- ( y ) — reprezentacja przyszłego stanu.
Model uczy się znaleźć ( \hat{y} ), które minimalizuje energię:
[
\hat{y} = \arg\min_y E(x, y)
]
W praktyce oznacza to minimalizację odległości między przewidywanym embeddingiem a rzeczywistym embeddingiem przyszłości.
Model nie rekonstruuje pikseli.
Model uczy się ewolucji struktury.
To ogromna różnica.
Problem kolapsu reprezentacji
W systemach typu JEPA istnieje niebezpieczeństwo tzw. kolapsu reprezentacji.
Model może nauczyć się trywialnego rozwiązania:
- mapować różne stany do podobnych wektorów,
- minimalizować błąd bez zachowania struktury świata.
Aby temu zapobiec, zastosowałem SIGReg (Sketched Isotropic Gaussian Regularization).
SIGReg – stabilność przez geometrię
Celem SIGReg jest wymuszenie, aby embeddingi ( z ) miały rozkład zbliżony do izotropowego Gaussa:
[
z \sim \mathcal{N}(0, I)
]
Taka przestrzeń:
- nie ma uprzywilejowanych osi,
- zachowuje różnorodność reprezentacji,
- zapobiega degeneracji modelu.
Mechanizm działa przez:
- Rzutowanie embeddingów na losowe kierunki.
- Testowanie zgodności z rozkładem normalnym (statystyka Eppsa–Pulleya).
- Dodanie kary do funkcji straty.
Efekt: model świata uczy się struktury, a nie skrótu.
Etap 2: Model świata jednego pokoju
Nie mając zasobów na trenowanie ogólnego modelu świata, przyjąłem strategię pionową.
Jedno środowisko.
22 godziny nagrań.
10 382 klipy po 8 sekund.
30 epok treningu.
Model nauczył się:
- geometrii pokoju,
- trajektorii kamery,
- typowych ruchów,
- relacji człowiek–przestrzeń.
Nie był to model świata w skali globalnej.
Był to model dynamiki konkretnego środowiska.
Eksperyment: przyszłość jako reprezentacja
Scenariusz wyglądał następująco:
- Kamera widzi teraźniejszość.
- V‑JEPA generuje reprezentację aktualnego stanu.
- EB‑JEPA generuje reprezentację za 8 sekund.
- Ta reprezentacja przechodzi przez Attentive Pooler.
- Trafia do LLM jako token wizji.
I tu kluczowe rozróżnienie:
LLM nie został poproszony o przewidywanie.
On po prostu opisywał to, co widzi.
A to, co widział, było już reprezentacją przyszłości.
Oczywiście istnieje opóźnienie generowania tokenów — LLM potrzebuje czasu na dekodowanie tekstu. Ale reprezentacyjnie przyszłość była dostępna natychmiast, bo została wcześniej wygenerowana przez EB‑JEPA.
LLM nie symulował fizyki.
Nie zgadywał.
Nie przewidywał samodzielnie.
On czytał przyszłość zapisaną w przestrzeni embeddingów.
I wtedy pojawiła się wątpliwość
System działał:
- Percepcja (V‑JEPA)
- Predykcja (EB‑JEPA)
- Interpretacja (LLM)
Ale gdy emocje opadły, w głowie pojawił się obraz.
Efekt starszej kobiety
Szklanka stoi na krawędzi stołu.
Ktoś lekko trąca stół.
Starsza kobieta mówi: „Zaraz spadnie.”
Czy liczy wektory siły?
Czy symuluje tarcie?
Nie.
Ma wzorzec.
Jej mózg nauczył się relacji:
szklanka + krawędź + szturchnięcie = upadekNie z równań.
Z doświadczenia.
Czy LLM to cyfrowa „babcia”?
LLM przeczytał miliardy tokenów.
Widział miliony zdań typu:
- „Nacisnął klamkę.”
- „Drzwi się otworzyły.”
Jeśli system widzi (dzięki V‑JEPA), że klamka się porusza,
czy naprawdę potrzebny jest model fizyczny zamka?
Może LLM już to „wie”.
Nie z fizyki.
Ze statystyki świata zakodowanej w języku.
Dwie drogi do przyszłości
Droga fizyczna (JEPA)
- modeluje ewolucję reprezentacji,
- operuje w przestrzeni struktury,
- daje stabilność dynamiczną,
- precyzyjna w trajektoriach.
Droga statystyczna (LLM)
- przewiduje skutek na podstawie wzorców,
- operuje w przestrzeni znaczeń,
- działa jak doświadczenie.
Jedno liczy.
Drugie rozpoznaje.
Wniosek
Nie trzeba wybierać obozu.
Można połączyć:
- percepcję,
- dynamikę,
- semantykę
przez wspólną przestrzeń reprezentacji.
W tym projekcie językiem stały się wektory.
V‑JEPA generował reprezentację.
EB‑JEPA przewidywał jej ewolucję.
LLM nadawał jej znaczenie.
Czas przestał być sekwencją pikseli czy słów.
Stał się trajektorią w przestrzeni embeddingów.
To nie jest dowód na AGI.
To nie jest ogólny model świata.
To eksperyment.
Ale pokazuje coś ważnego:
Przyszłość może być reprezentacją.
A reprezentacja może być wspólnym językiem między różnymi typami modeli.
I być może to nie wojna obozów jest przyszłością AI,
lecz ich synchronizacja.
Informacje dodatkowe:
https://github.com/facebookresearch/eb_jepa
https://arxiv.org/pdf/2602.03604
https://arxiv.org/pdf/2506.09985
** Ania11B – Własny model /pełne dostrojenie 16bit/ oparty na Modelu Bielik 11B v2.6
Wersja artykułu w języku angielskim:
https://medium.com/@brainhome9/can-an-llm-see-the-future-e0135402f42c