Czy LLM może „zobaczyć” przyszłość?
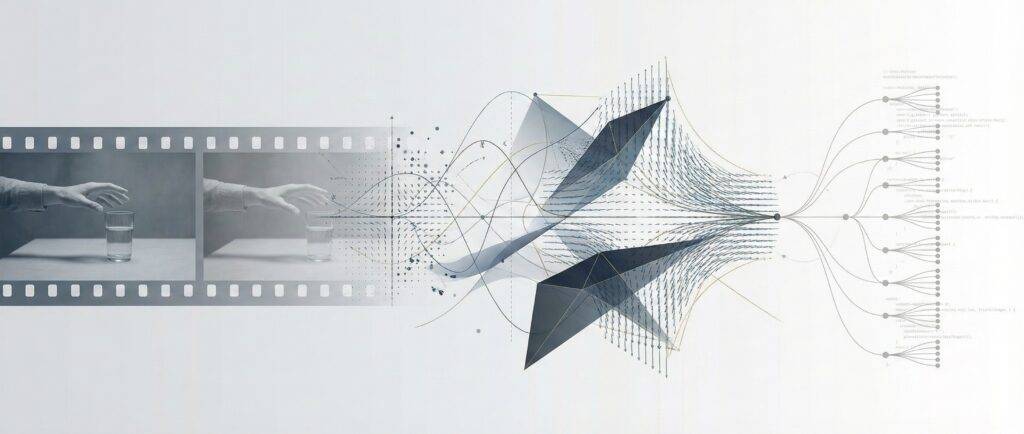
Czy LLM może „zobaczyć” przyszłość? Eksperyment z modelami świata, reprezentacją latentną i wspólnym językiem wektorów Nie zacząłem tego projektu po to, żeby udowodnić komuś rację albo ją podważyć. Zacząłem go z czystej ciekawości. W sztucznej inteligencji od kilku lat narasta napięcie. Jedni twierdzą, że wystarczy skalować modele językowe — więcej tekstu, więcej parametrów, więcej danych …