
Phi-1.5 oraz Phi-1 – Małe, ale potężne. Czy biją gigantyczne modele sztucznej inteligencji?
W świecie, gdzie dynamika rozwoju technologii sztucznej inteligencji przybiera na sile, modele Phi-1 oraz Phi-1.5 stawiają nowe wyzwania dotyczące klasycznych paradygmatów rozwijania AI. Wprowadzone przez Microsoft, te modele pokazują, że sukces w dziedzinie programowania AI nie zawsze zależy od skali, ale od jakości oraz technik szkolenia. Jak te modele przekształcają podejście do sztucznej inteligencji?
W ciągu ostatnich lat duże modele językowe, takie jak GPT-3, pokazały potencjał skalowania parametrów oraz danych treningowych w generowaniu tekstu. Jednak przyniesienie tego podejścia do generowania kodu komputerowego nie przyniosło oczekiwanych rezultatów. Tutaj wkraczają Phi-1 oraz Phi-1.5.
Kluczowa innowacja Phi-1: Użycie wysokiej jakości danych w stylu „podręcznikowym” do wstępnego szkolenia. Dzięki temu model wykazał zdolności rozumowania i rozwiązywania problemów na poziomie dużo większych modeli, mając jednocześnie znacznie mniejszą skalę.
Phi-1.5 – kolejny krok w ewolucji: Biorąc pod uwagę sukcesy i ograniczenia Phi-1, Microsoft rozwinął Phi-1.5, wprowadzając dalsze usprawnienia w danych i metodologii szkolenia. Ten model został wyposażony nie tylko w umiejętności kodowania, ale także w silne umiejętności odpowiadania na pytania, rozumowanie w zakresie zdrowego rozsądku i rozwiązywanie złożonych problemów logicznych.
Innowacje architektoniczne Phi-1.5: Tak jak jego poprzednik, Phi-1.5 korzysta z wydajnej architektury, która maksymalizuje uczenie się z jego metodyki szkolenia. Co ważne, nie zwiększa to liczby parametrów w porównaniu z Phi-1.
Wydaje się że Phi-1.5 i Phi-1 to małe, ale potężne modele sztucznej inteligencji, które kwestionują dotychczasowe podejście do rozwoju AI. Poprzez koncentrację na jakości danych szkoleniowych i innowacyjnych technikach, te modele oferują nową perspektywę na przyszłość programowania w dziedzinie sztucznej inteligencji. W erze, w której skala była uważana za klucz do sukcesu, Microsoft pokazuje, że może być inaczej.
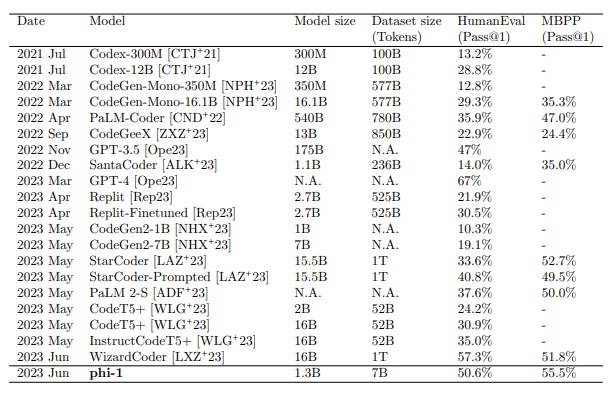
Na podstawie: https://arxiv.org/pdf/2306.11644.pdf