
Od Teorii do Praktyki: Jak BitNet b1.58 zmienia zasady gry w Sztucznej Inteligencji
Modele językowe, zbudowane na architekturze Transformera, typowo operują w precyzji 16-bitowej (FP-16 lub BF-16), gdzie głównymi kosztami obliczeniowymi są operacje dodawania i mnożenia macierzy zmiennoprzecinkowych. W tych pełnoprecyzyjnych modelach, ładowanie wag z DRAM do pamięci akceleratora na chipie (np. SRAM) generuje wysokie koszty podczas inferencji.
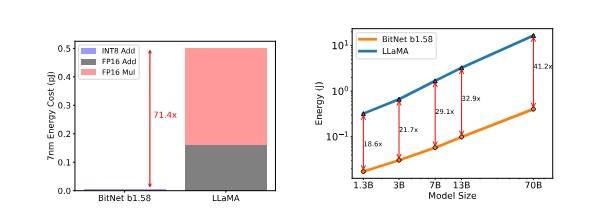
BitNet b1.58 wprowadza efektywną zmianę, redukując precyzję do wartości ternarnych {-1, 0, 1}, dzięki czemu eliminuje konieczność mnożenia zmiennoprzecinkowego, angażując tylko dodawanie całkowitoliczbowe (INT-8) i efektywnie ładowanie parametrów z DRAM. Ta technologia nie tylko demonstruje oszczędność kosztów w zakresie latencji, pamięci, przepustowości i zużycia energii, ale także utrzymuje, a nawet przewyższa pełnoprecyzyjne bazowe modele Transformerów pod względem złożoności i wydajności końcowego zadania.
Czy BitNet b1.58 może zastąpić modele Float 16?
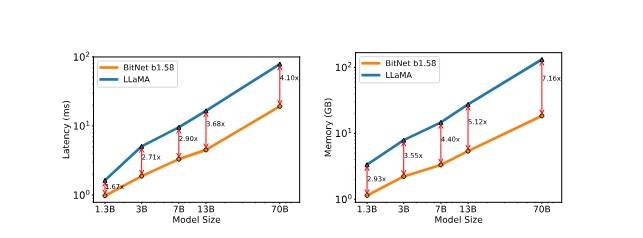
Autorzy BitNet b1.58 porównali go z odtworzonym modelem FP16-LLaMA, trenując oba modele z tymi samymi konfiguracjami i oceniając wydajność zero-shot na różnych zadaniach językowych. Wyniki ujawniają, że BitNet b1.58 zaczyna dorównywać LLaMA przy rozmiarze modelu 3B i kontynuuje zmniejszanie luki w wydajności, przewyższając modele o pełnej precyzji pod względem złożoności i wyników końcowego zadania. Szczególnie model BitNet b1.58 o rozmiarze 3.9B był 2,4 raza szybszy i zużywał 3,32 raza mniej pamięci niż LLaMA 3B, redukując koszty pamięci i latencji.
Dodatkowe eksperymenty ujawniły, że BitNet b1.58 70B był 4,1 raza szybszy i miał 8,9 raza większą przepustowość niż odpowiadający model FP16 LLaMa.
Eksperyment z BitNetem 1.58 LLM
Nous Research przeszkoliło model BitNet 1B, OLMo-BitNet-1B na pierwszych 60B tokenach zestawu danych Dolma, a także standardowy model FP16 OLMo-1B z tymi samymi konfiguracjami treningowymi dla porównania wydajności. Wyniki wykazały, że OLMo-1B odnotował nieznacznie lepszą złożoność i stratę entropii krzyżowej niż OLMo-BitNet-1B na wszystkich podzbiorach zestawu danych Dolma.
Głębsze spojrzenie na BitNet b1.58: Analiza wydajności i oszczędności
Innowacja BitNet b1.58 leży w jej zdolności do operowania na wagach w sposób, który zmniejsza zapotrzebowanie na pamięć i moc obliczeniową, jednocześnie utrzymując, a nawet przewyższając, dokładność modeli operujących w precyzji 16-bitowej. To stawia przed nami pytanie: jak ta technologia wpływa na praktyczne zastosowania modeli językowych?
Przypadki użycia i aplikacje
- Rozwój osobisty i edukacja: Dzięki mniejszemu zapotrzebowaniu na zasoby, BitNet b1.58 umożliwia indywidualnym użytkownikom i edukatorom wdrażanie zaawansowanych modeli językowych na domowych komputerach, otwierając nowe możliwości w nauczaniu maszynowym i sztucznej inteligencji.
- Przemysł technologiczny i badania: Firmy i instytucje badawcze mogą korzystać z BitNet b1.58 do przyspieszenia swoich badań i rozwoju produktów AI, zmniejszając koszty infrastruktury i energii.
- Sektory o ograniczonych zasobach: Organizacje w krajach rozwijających się lub instytucje z ograniczonym budżetem na badania mogą teraz wykorzystywać potężne modele językowe bez potrzeby inwestowania w drogą infrastrukturę obliczeniową.
Tabele i Wykresy
Analizując wyniki eksperymentów, warto zwrócić uwagę na konkretne liczby. Przykładowo, w eksperymencie z modelem 70B, BitNet b1.58 osiągnął przewagę 4,1 razy w szybkości i 8,9 razy w przepustowości w porównaniu do modeli FP16 LLaMa. Taka różnica w wydajności i efektywności otwiera nowe horyzonty w zastosowaniu modeli językowych w realnych aplikacjach.
Wnioski i przyszłość BitNet b1.58
Nowy rodzaj kwantyzacji stanowi kamień milowy w rozwoju modeli językowych, oferując rozwiązanie, które może zdemokratyzować dostęp do zaawansowanej sztucznej inteligencji. Jego zdolność do konkurowania z modelami pełnej precyzji, przy znacznie niższym zapotrzebowaniu na zasoby, podkreśla potencjał dla przyszłych innowacji i badań w dziedzinie AI. Przy odpowiednim wsparciu i adopcji, BitNet b1.58 ma potencjał nie tylko do zmniejszenia barier wejścia dla badań AI, ale również do wprowadzenia nowych standardów w energetycznej efektywności i dostępności technologii.
na podstawie:
https://arxiv.org/pdf/2402.17764.pdf
https://medium.com/@zaiinn440/llama-bitnet-training-a-1-58-bit-llm-3831e517430a