DeepMind MoR: Gdy rekurencja zwiększa efektywność LLM
W konwencjonalnych modelach językowych dominuje proste równanie: większa inteligencja wymaga więcej warstw. Więcej parametrów, większe zapotrzebowanie na moc obliczeniową, wyższe zużycie energii. Inżynierowie Google DeepMind postawili inne pytanie: jak osiągnąć więcej przy mniejszych zasobach? Odpowiedzią jest Mixture-of-Recursions (MoR) – architektura oparta nie na dodawaniu, lecz inteligentnym powtarzaniu. Rezultaty? Podwojenie prędkości inferencji, 50-procentowa redukcja zapotrzebowania na pamięć oraz znaczący postęp w adaptacyjnym rozumowaniu, potwierdzony zarówno testami syntetycznymi, jak i zadaniami wymagającymi niestandardowego podejścia.
Rekurencja: Nowe zastosowanie starej koncepcji
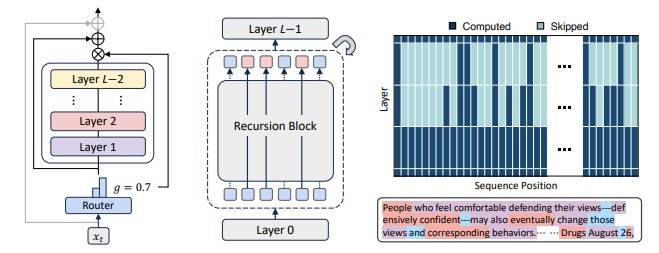
Podczas gdy transformery działają jak liniowa taśma produkcyjna, a architektura Mixture-of-Experts (MoE) przypomina komitet specjalistów, MoR wprowadza prostą zasadę: ten sam blok wag stosowany jest rekurencyjnie, a liczba powtórzeń zależy od złożoności tokena.
Kluczowe elementy MoR w porównaniu z tradycyjnymi rozwiązaniami:
- Dynamiczny routing tokenów: Lekki router decyduje, ile iteracji wymaga dany token. Proste elementy (spójniki, liczebniki) przechodzą jednokrotnie, złożone (zaimki wymagające interpretacji kontekstu) – wielokrotnie. Pozwala to optymalnie rozłożyć zasoby obliczeniowe.
- Selektywne buforowanie KV: Cache powiązany jest zarówno z pozycją tokena, jak i poziomem rekurencji. Minimalizuje to operacje pamięciowe – dla każdej głębokości przechowywane są tylko niezbędne dane.
- Współdzielenie parametrów: Jeden blok wag stosowany rekurencyjnie zamiast duplikowania parametrów dla każdej warstwy. Umożliwia dynamiczne dostosowanie „głębokości przetwarzania” bez zwiększania rozmiaru modelu.
Te mechanizmy sprawiają, że MoR traktuje tekst jako sieć logicznych ścieżek, z których każda wymaga indywidualnego podejścia.
Wyniki testów
Benchmarki potwierdzają efektywność architektury:
- 2x szybsza inferencja – W testach na Wikitext-103 i MMLU, MoR osiągał dwukrotnie wyższą prędkość generowania tokenów niż tradycyjne transformery przy tej samej liczbie parametrów.
- 50% mniejsze zużycie pamięci KV cache – Dla 7-miliardowego modelu MoR wymagał średnio 1.7 GB VRAM, podczas gdy odpowiadający mu transformer potrzebował ponad 3.3 GB.
- Redukcja FLOPów podczas treningu – Do 45% mniej operacji zmiennoprzecinkowych, co przekłada się na krótszy czas uczenia i niższe koszty.
- Lepsze wyniki w zadaniach rozumowania – W testach logicznych (Winograd Schema Challenge, ocena ironii) MoR przewyższał zarówno transformery, jak i MoE, osiągając w benchmarku SuperGLUE o 4 punkty procentowe lepsze wyniki.
Te wartości przekładają się na realne korzyści: możliwość uruchamiania zaawansowanych modeli na słabszym sprzęcie i lepszą obsługę złożonych zadań.
Wyzwania implementacyjne
MoR wprowadza nowe problemy techniczne:
- Problem brakujących danych KV: Gdy token kończy przetwarzanie wcześniej, głębsze warstwy mogą nie mieć dostępu do jego danych. DeepMind stosuje synchronizację cache i block-wise KV caching.
- Ograniczenia równoległości: Nieregularny przepływ danych utrudnia pełne równoległe dekodowanie. Rozwiązania obejmują częściowe buforowanie stanów i selektywne unmasking.
- Zarządzanie routingiem: Konieczność balansowania obciążenia i zabezpieczeń przed przeciekaniem informacji między ścieżkami.
Skuteczna implementacja wymaga połączenia recursion-wise caching, mechanizmów równoważenia obciążenia i confidence-aware decoding.
Dlaczego MoR ma znaczenie praktyczne?
- „Głębia myślenia” dla agentów AI: Systemy operujące w rzeczywistych warunkach lepiej radzą sobie z niepełnymi danymi dzięki adaptacyjnemu przetwarzaniu.
- Demokratyzacja LLM: 7-miliardowy model MoR działa w czasie rzeczywistym na smartfonie z 8 GB RAM, podczas gdy tradycyjny transformer wymagałby znacznie większych zasobów.
- Ekologia obliczeń: Według DeepMind, MoR może obniżyć zużycie energii przy wdrażaniu LLM o 35% w porównaniu z klasycznymi architekturami.
- Elastyczność wdrożeń: Łatwe skalowanie od serwerów po urządzenia brzegowe bez głębokich modyfikacji.
„MoR to powrót do podstaw: zamiast zwiększać moce obliczeniowe, sprawiamy, że każdy cykl pracuje efektywniej” – komentuje dr Anika Patel z MIT.
Kierunki rozwoju
DeepMind proponuje nową filozofię projektowania LLM – skupienie na głębi zamiast na skalowaniu. Kluczowe obszary rozwoju:
- Optymalizacja dekodowania: Udoskonalanie synchronizacji i buforowania dla wydajniejszego przetwarzania wsadowego.
- Integracja wielomodalna: Rozszerzenie MoR na przetwarzanie obrazu, dźwięku i danych sensorycznych.
- Standaryzacja: Upowszechnienie architektury poprzez integrację z popularnymi frameworkami.
Perspektywa: Poza technicznymi aspektami, MoR oferuje społeczną wartość – obniża bariery dostępu do zaawansowanej AI. Może to przyspieszyć adopcję technologii w edukacji, medycynie czy walce z dezinformacją, pokazując alternatywną drogę rozwoju sztucznej inteligencji.