GPT-5: Nowy Język Inteligencji i Współpracy Człowiek-Maszyna
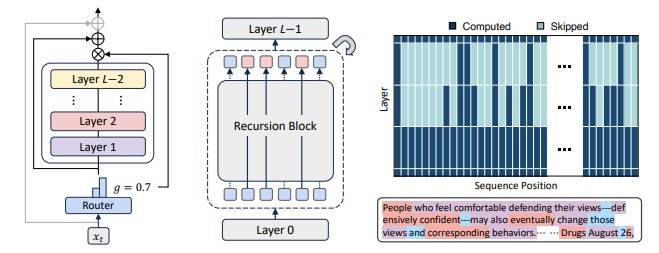
Zapowiedź GPT-5 od OpenAI budzi szczególne napięcie w środowisku technologicznym. To nie jest zwykła aktualizacja – model zapowiada jakościową zmianę w relacjach człowieka z maszyną, przesuwając punkt ciężkości z wydajności na głęboką współpracę. Wielomodalność jako spójna percepcja Deklarowana „ulepszona wielomodalność” GPT-5 wykracza poza rozwiązania znane z GPT-4 czy GPT-4o. Podczas gdy poprzednie modele obsługiwały różne …