DeepMind MoR: Rekurencja zwiększa wydajność modeli językowych
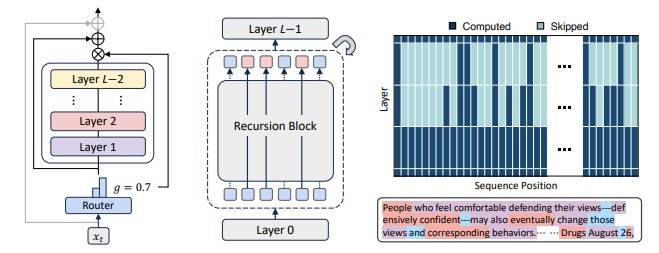
DeepMind MoR: Gdy rekurencja zwiększa efektywność LLM W konwencjonalnych modelach językowych dominuje proste równanie: większa inteligencja wymaga więcej warstw. Więcej parametrów, większe zapotrzebowanie na moc obliczeniową, wyższe zużycie energii. Inżynierowie Google DeepMind postawili inne pytanie: jak osiągnąć więcej przy mniejszych zasobach? Odpowiedzią jest Mixture-of-Recursions (MoR) – architektura oparta nie na dodawaniu, lecz inteligentnym powtarzaniu. Rezultaty? …